Por probar, vaya:
https://mirinconeninternet.substack.com/
Está claro que estas herramientas ya han cambiado la forma en la que muchos trabajamos, pero da un poco de miedo pensar que estemos usándolas para lo que no están pensadas o para lo que no estén capacitadas.
Esto era cladude.ai con Sonet 4.6
Seguro que otros modelos no fallan en estas cosas, de acuerdo, pero el asunto no es qué tan bueno o no es un modelo.
El asunto es que son herramientas falibles para algunas tareas pero que aportan una sensación de seguridad que no se corresponde con la realidad.
Como el candado verde en los navegadores cuando visitas una página con un certificado SSL "de los buenos". Ah, bueno, tiene candado, es una página segura. Y resulta que la página tenía una vulnerabilidad SQL injection que le habían robado toda la base de datos.
Pues con estas herramientas va empezando a calar la sensación y el discurso de "si lo ha escrito Gemini/Claude/ChatGPT/... estará bien".

Retomando problemas del proyecto Euler, este en principio es bastante fácil.
https://projecteuler.net/problem=37

Es relativamente fácil, por ejemplo, con Python, convertir el número a string, ir quitando caracteres por la derecha y comprobando cada vez si el número que queda es primo. Luego, lo mismo por la izquierda.
Mi primera implementación no tuvo en cuenta que no se considera "truncatable" si terminas con un 1. Lo mismo deberían decirlo en el enunciado, lo mismo es falta de cultura matemática por mi parte.
La función is_truncable, que se muestra a continuación, utiliza una función is_prime para trabajar. Va probando casos para probar que los números que van quedando son primos o no. Si después de analizar por la derecha y la izquierda todos han resultado ser primos, asume que es "truncable".
Antes de eso, hemos hecho una pequeña función para generar una lista de números primos:
Y una función main() que monta todo el proceso:
En la primera implementación de is_prime() que hice, sin ninguna optimización, propia de un estudiante de ESO, simplemente iba dividiendo el número en cuestión por todos los números más pequeños que él mismo, si encontraba algún divisor, entonces no era primo.




Supermercado en Madrid, en el vestíbulo tienen una pantalla con autopromos, etc... y una ventana de TeamViewer en la que se ve el ID del equipo.

Si ya la web estaba llena de basura pensada para el bot de Google, ahora se le va a unir la basura generada por ChatGPT 🤦🤦🤦







Está claro que los grandes (Facebook, Twitter, Google,...) viven de la publicidad. Está claro que su único interés es generar impresiones y cobrarlas, pero cuando los anuncios que publican son estafas, tienen una responsabilidad.
Algunas plataformas empiezan a cuidar este tema y retiran anuncios de estafas, pero otras no son tan escrupulosas.
¿Hasta cuando se va a permitir esto? Muestrario de anuncios de Facebook:

















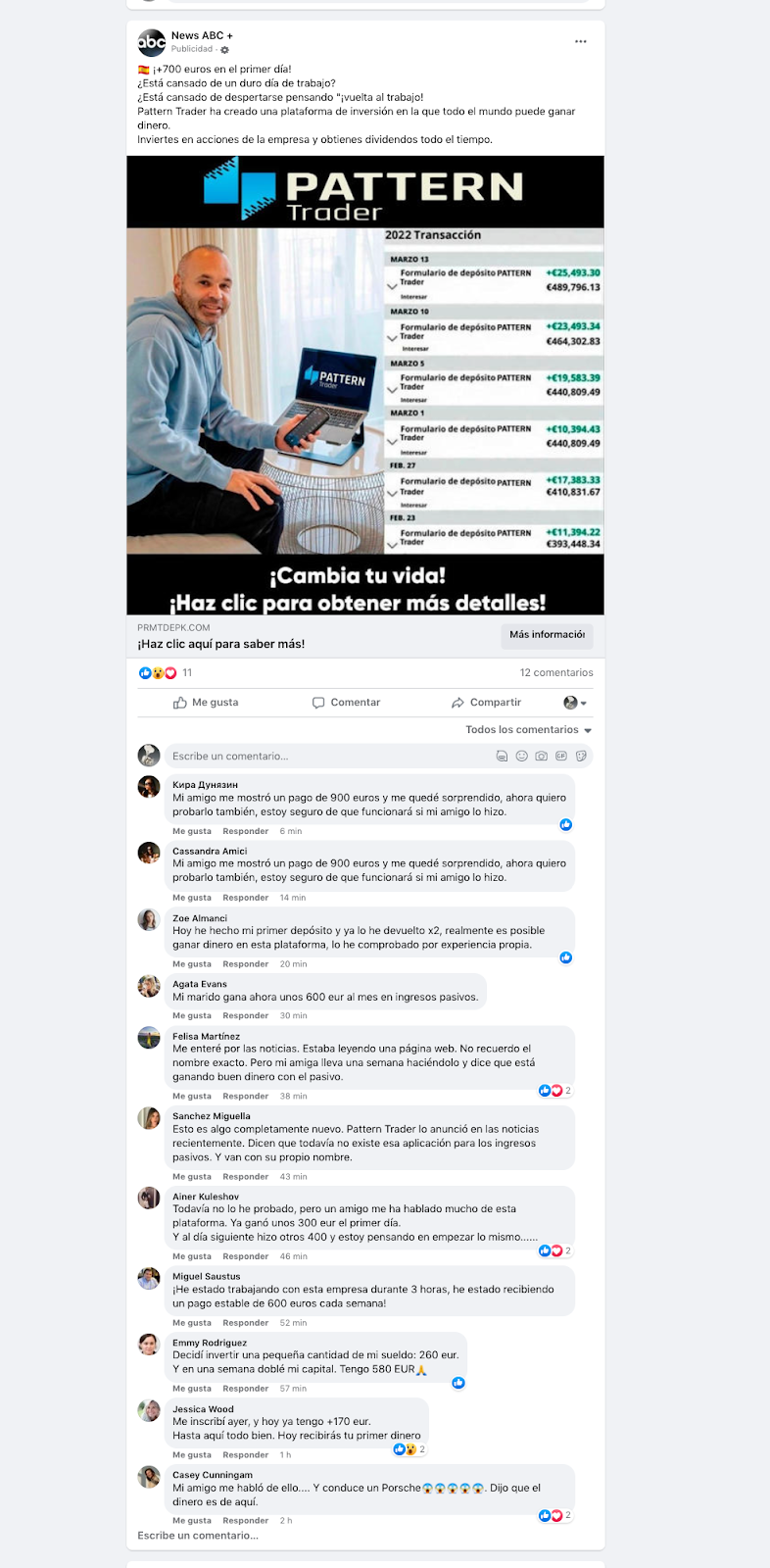
Famosos participando en productos financieros de alto riesgo...
https://cincodias.elpais.com/cincodias/2021/11/28/mercados/1638112255_177308.html

Lo más triste del asunto es que si estos anuncios se publican es porque hay un "target" potencial, gente hastiada de trabajar, criptolais, tontokens, ninis variados... la pena es cuando engañan a gente que simplemente quería rentabilizar sus ahorrillos.
Situación: nos pasan una instalación de wordpress en la que no se sabe la contraseña de algún usuario del wp-admin, el correo de restablecimiento es de pruebas o no tenemos acceso a dicho buzón.
 |
| Ejemplo: un usuario con un correo inventado de pruebas |
Si vamos a recuperar contraseña, nos pide el correo, que puede ser inventado o no tener acceso:

Solución: si tenemos acceso a la base de datos (por línea de comandos o alguna herramienta tipo phpMyadmin, típica de los proveedores de hosting), solo hay que establecer la contraseña cifrándola con MD5.

Aunque Wordpress utiliza un sistema más robusto de contraseñas, con salt y demás, sí que reconoce las cifradas en MD5.
Una vez que ya tenemos acceso con la nueva contraseña, podemos ir al wp-admin/users.php y establecer una contraseña de nuevo para el usuario, esta vez estará convenientemente cifrada y salteada. MD5 a día de hoy es totalmente inseguro, es casi como guardar en plano.
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9])|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
Fuente: https://stackoverflow.com/a/201378


array2 = array1 = {'uno': 1, 'dos': 2} print('array1 antes:', array1) print('array2 antes:', array2) array2['dos'] = 22 array1['tres'] = 3 print('array1 después:', array1) print('array2 después:', array2)
~ $ python3 testarray.py array1 antes: {'uno': 1, 'dos': 2} array2 antes: {'uno': 1, 'dos': 2}
array1 después: {'uno': 1, 'dos': 22, 'tres': 3} array2 después: {'uno': 1, 'dos': 22, 'tres': 3}
<?php $array1 = $array2 = array("uno" => 1, "dos" => 2); echo "array1 antes:"; var_dump($array1); echo "\n"; echo "array2 antes:"; var_dump($array2); echo "\n"; $array1["tres"] = 3; $array2["dos"] = 22; echo "array1 después:"; var_dump($array1); echo "\n"; echo "array2 después:"; var_dump($array2); echo "\n";
~ $ php testarray.php array1 antes:array(2) {["uno"]=> int(1), ["dos"]=> int(2)} array2 antes:array(2) {["uno"]=> int(1), ["dos"]=> int(2)} array1 después:array(3) {["uno"]=> int(1), ["dos"]=> int(2), ["tres"]=> int(3)} array2 después:array(2) {["uno"]=>, int(1), ["dos"]=> int(22)}¿Qué ha pasado en este caso? Las dos variables son independientes, los cambios en una no afectan a la otra. Cada una apunta a una región de memoria diferente. En PHP se puede conseguir el mismo comportamiento que en otros lenguajes, esto es, que asignar una variable a otra por referencia:
<?php $array1 = array("uno" => 1, "dos" => 2); $array2 = &$array1; echo "array1 antes:"; var_dump($array1); echo "\n"; echo "array2 antes:"; var_dump($array2); echo "\n"; $array1["tres"] = 3; $array2["dos"] = 22; echo "array1 después:"; var_dump($array1); echo "\n"; echo "array2 después:"; var_dump($array2); echo "\n";